mThe following sections give some information relevant to retrieving data efficiently.
Request scheduling
The main archive implements a queuing system necessary to satisfy all type of requests: time-critical operational tasks, interactive users retrieving a few fields for visualisation, batch users retrieving Gigabytes of data, etc.
Resources available on the main archive impose some limitations on the number of requests processed simultaneously: these resources are basically the number of Unix processes MARS can start and the number of drives available to read data from tapes. The cost of a request is evaluated on arrival in terms of number of fields requested and their location, either on disk or on tape. The more tapes a request has to access, the more likely that it will be queued. It is possible that requests will be queued if the MARS server reaches certain limit of concurrent requests.
The queuing system handles priorities: the request with the highest priority will be chosen next for execution. This priority is computed from the age of a request since it entered the queue. An artificial mechanism of ageing requests allows to prioritise operational work or interactive users. You can view the MARS queue online.
Data collocation
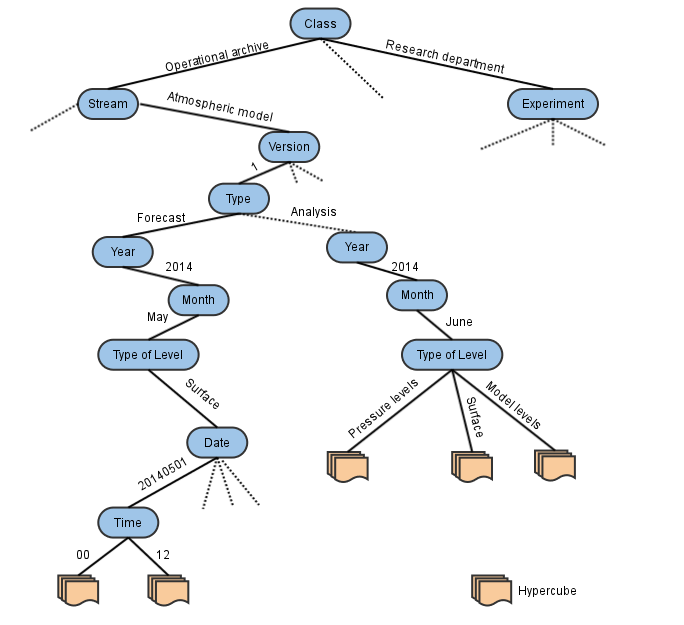
A request is scheduled more efficiently if it minimises the number of tapes it has to access in order to be satisfied. To create efficient MARS requests you must know how the data is organised.
The MARS system is organised in a tree fashion based on MARS keywords. At the bottom of the tree there are what we called the hypercubes or archive objects, that are aimed to be in a single file on tape. There is a compromise between the amount of data these cubes hold and the relationship between the data they contain. By studying data access patterns, we have come up with the following rules:
- 1 file per month of Analysis (1 type of level, all times, levels, and parameters), for example, have a look in the MARS Catalogue for February 2015 model level analysis
- 1 file per Forecast (1 type of level, all steps, levels and parameters), for example, have a look in the MARS Catalogue for 1st February 2015 model level forecast at 12 UTC
- 1 file per Ensemble Forecast (1 type of level, all steps, members, levels and parameters), for example, have a look in the MARS Catalogue for 1st February 2015 pressure level 50 member ensemble at 12 UTC
Different projects have different needs, and therefore these rules may vary. You are encouraged to visit the MARS Catalogue to inspect how much related data a hypercube contains. The description above is the rule, but resources available at certain times might cause to break it, e.g. 1 month of Analysis may be in 2 files because at that particular month the MARS system was short of disk space and data had to be written to tape earlier than desired.
Post-processing
Any requested data manipulation or post-processing is carried out by the MARS client, except in the case of the Web API client where data is first processed at ECMWF prior to its transmission over the network. The post-processing is carried out by MIR, a library of routines for Meteorological Interpolation and Regridding (see ECMWF newsletter no.152 for a description). For details on the various operations please see also the relevant post-processing keyword descriptions.
Sub-area extraction
Most of the data at ECMWF is global. A sub-area can be created using the area keyword by defining its latitude and longitude boundaries: North/West/South/East.
Global grids have a grid mesh implicitly based on (0 W, 0 N); the grids do not wrap around at (0 E, 360 W). For example, a 3x3 degree grid has latitudes at 90 N, 87 N,..., 87 S, 90 S and longitudes at 0 E, 3 E,..., 354 W, 357 W. Sub-areas are created from a global grid using the same implicit origin and spacing; if necessary, the sub-area boundaries are adjusted to fit on the grid mesh by enlarging it.
Polar latitudes are made up of repeated grid-point values; a wind V-component has an adjustment for longitude. Gaussian grids do not have a latitude at either Pole or at the Equator.
Sub-area extraction is possible for regular Gaussian and latitude longitude fields (including wave). They cannot be applied if the resulting field is in spherical harmonics or reduced (quasi-regular) representation.
Conversion of horizontal representations
The following conversions (interpolations) of horizontal representations are available:
- reduce the triangular truncation of spherical harmonic fields, e.g. resol=319
- change the resolution of Gaussian grids, e.g. grid=42
- change the resolution of latitude/longitude grids, e.g. grid=5/5
- convert spherical harmonic to Gaussian grids, e.g. grid=160, gaussian=reduced
- convert spherical harmonics to latitude/longitude grids, e.g. grid=2.5/2.5
- convert quasi-regular Gaussian grids to regular Gaussian grids, same or different resolution, e.g. grid=160, gaussian=regular
- convert Gaussian to latitude/longitude grids, e.g. grid=2.5/2.5
Derived fields
Some fields are not archived but are derived from others. This is the case for wind components (U and V), which are derived from vorticity and divergence.
Accuracy
GRIB coded fields have a specified number of bits per packed value which can be changed with keyword accuracy. This might be useful when trying to retrieve fields from MARS identical to those you get from dissemination.
There is no gain in precision by using a value higher than the number of bits originally used for archiving.
Truncation before interpolation
By default spectral fields are automatically truncated before interpolation to grid fields to reduce data volumes and spurious aliased values. The truncation can be controlled using the keywords truncation and intgrid. Users wanting to post-process at the full archived resolution can specify truncation = none in the request.
Note that high resolutions might need more resources to carry out post-processing.
Retrieval efficiency
To retrieve data efficiently please follow the hints below:
- Whenever possible, use a local file system to store the target file (e.g. $SCRATCH on ecgate for external users) as this will avoid unnecessary network traffic.
- Estimate the data volume to be retrieved before issuing a request. It is easy to retrieve Gigabytes of data. Check that computer resources and limits are adequate for the amount of data to retrieve/interpolate in order to avoid unnecessary processing (MARS will fail if a quota is exceeded or in the case of any Unix problem regarding resources such as memory or CPU time).
- Estimate the number of fields to be retrieved before issuing a request. Try to retrieve a sensible number, up to tens of thousands of fields.
- Reduce the number of tapes involved. The number of tapes a MARS request is going to access will have an impact on its scheduling on the server. As a rule of thumb, two or more separate requests accessing files on different tapes are scheduled more efficiently than a single request accessing two or more tapes. A large number of tapes implies more waiting time. Use multiple requests in one MARS call whereby all the data is written to one output file.
- When retrieving large datasets (e.g. Re-Analysis), try to retrieve as many data from the same tape file as possible. Then, avoid caching the data on the server by specifying use = infrequent.
- Avoid constantly accessing the same tape. If you issue a large number of requests, all accessing data on the same tape, this can keep that tape in the drive for many hours and potentially cause some damage. Once you access a tape read as many fields as possible and if needed split the output by level, parameter etc. using the multi-target feature. This would reduce the amount of requests and make your extractions much faster.
Please also follow the Guidelines to write efficient MARS requests.
Troubleshooting
Syntactic errors
If a comma is missing or an unknown MARS keyword is specified, MARS will stop processing your request and report a syntax error.
Semantic errors
MARS does not perform any semantic check on the request. A MARS request can be syntactically correct but may not describe any archived data. Common problems are:
- Data not found
Usually means the MARS directives do not specify archived data. - Expected xx, got yy
The server transferred some data and the client failed; usually the client expected more fields than were sent by the server. Either some data do not exist, are missing on the server or a syntactically correct request asked for a parameter which is not in MARS. - Inconsistency in field ordering
This error occurs when a server sends a field which does not correspond to the MARS request. Operational servers are not likely to deliver inconsistent data, but it may well happen in test environments.
If you get this kind of error when retrieving monthly means, then setting the day to 00 (DATE=YYYYMM00) will solve the problem.
System limits
Some system resource limits can be controlled by the user (consult the man pages of your shell if running in interactive mode or documentation about the software used for batch mode).
Error writing to file
It usually indicates the user has exceeded his/her quota on the filesystem holding the target file or that filesystem became full.Memory allocation failed
It usually indicates MARS needs more memory than the available for user processes in order to execute a request.CPU time limit
It usually indicates the MARS process has exceeded the CPU time limit. The kind of post-processing and the number of fields retrieved have a direct implication of the CPU time needed by MARS to satisfy a request.
MARS keyword = all
By using the value all on certain keywords, MARS is asked to retrieve ALL data available which matches the rest of the request. In some cases, all data available is not all the data you expect. The use of all is best avoided.
It should be noted that retrievals from the Fields Data Base do not accept all as a valid value.
Failed HPSS call
Messages starting with Failed HPSS call: n = ::hpss_Read(fd_,buffer,... are HPSS errors. The actual message text can vary but they usually mean that the data is unavailable from tapes for some time. These errors are passed to the client and make your request fail. As a rule, after checking that there is no ongoing system session, re-run your request before reporting the error. If the failure is consistent, please inform ECMWF's Service Desk.
Assertion failed
Error messages starting with Assertion failed: followed by offset[i] > offset[i-1] or handle[n] != 0 hint at an attempt to retrieve the same field more than once, e.g. by specifying param=z/t/z or step=24/48/24. The actual message varies depending on how exactly the data is retrieved. The general advice in such cases is to check the request for multiple occurrences of keyword values.
Debugging
Some failures are not evident to explain from the MARS report. In such cases, you can turn on debug messages by setting environment variable MARS_DEBUG to any value different from 0.
Please, note that running in debug mode can generate large amount of output, therefore you are advised to re-direct MARS output to a file.
Default values
MARS will guess unspecified keywords in a request and will assign default values to them. Some default values are not valid in the context of all possible retrieve requests. Avoid their use as far as possible.
Set of working requests
It is advisable to have a set of working requests and to re-use or modify them as needed.
Report
At the end of each request, MARS will print a report on all the aspects of its execution:
- which server delivered the data
- number of fields/reports which have been retrieved/interpolated
- time spent in retrieving/interpolating
- network transfers
- memory usage
- the most wanted message: No errors reported
This report gives users an idea about the resources needed for a request, and can be used for future reference when retrieving similar datasets.
MARS messages
MARS has the following levels for messages it prints on execution:
| INFO | request being processed and a report on the execution at the end |
| DEBUG | additional information if debugging is switched on |
| WARNING | any unusual aspect of the execution |
| ERROR | system or data errors which do not stop MARS execution |
| FATAL | terminates the execution of MARS |
Field order
Do not expect retrieved fields to be returned in any specific order. Depending on the MARS configuration, fields can be retrieved differently. Therefore, user programs processing the target file must take this into account.
It is possible to obtain always the same sequence, i.e. order of fields in the request, by using fieldsets.
Avoid sub-archives
Avoid creating sub-archives in file based storage systems, e.g. ECMWF's ECFS. This system does not provide data collocation, and a future access to the same data will usually be slower than retrieving it again from MARS. Unless data has been post-processed, do not store Gigabytes of MARS data in ECFS.
8 Comments
Unknown User (cuh)
I am currently getting the error "Assertion failed: offset[i] > offset[i-1] in process, line 141 of /users/maxtest/git/mars-server/src/reader/reader.t.cc [marser]".
From the above, I understand that this is happening because I am retrieving the same field more than once.
I am currently testing the best setup to download a list of variables, globally, for the full available period. As such I am indeed testing this on the same field. I could of course do these tests for different timesteps, but I guess that, once I will start downloading all of the required data, I might bump into this issue again?
Is is possible to explain how this behaviour can be circumvented?
Thanks!
Unknown User (data.request@geos.com)
I am getting the same error do you know why is that?
Carsten Mass
E.g. it could be that you are trying to retrieve monthly data with
date=19000101/to/19001201,
rather than
date=19000101/19000201/19000301/...
I suggest you send your request (ideally with some log) to advisory@ecmwf.int so that we can investigate.
Thanks
Carsten
Unknown User (fabian.arandia@gmail.com)
Hi,
We are currently downloading TIGGE data from 3 meteorological models. Curiously the ECMF data downloads faster than the KWBC data even though they are less volominous:
(Kwbc 3-4h between each request)
-rw-rw-r-- 1 cs6292 cs6292 6867746 Jul 26 12:15 mx2t6-mn2t6-tp-20161212-day1to15-kwbc-all.grib
-rw-rw-r-- 1 cs6292 cs6292 6861342 Jul 26 14:48 mx2t6-mn2t6-tp-20161213-day1to15-kwbc-all.grib
-rw-rw-r-- 1 cs6292 cs6292 6810898 Jul 26 18:07 mx2t6-mn2t6-tp-20161214-day1to15-kwbc-all.grib
-rw-rw-r-- 1 cs6292 cs6292 6798246 Jul 26 21:51 mx2t6-mn2t6-tp-20161215-day1to15-kwbc-all.grib
-rw-rw-r-- 1 cs6292 cs6292 6772701 Jul 27 01:07 mx2t6-mn2t6-tp-20161216-day1to15-kwbc-all.grib
(Ecmf : 50 min average….there's long interruptions also)
-rw-rw-r-- 1 cs6292 cs6292 248418000 Aug 2 00:48 mx2t6-mn2t6-tp-20160331-day1to15-ecmf-all.grib
-rw-rw-r-- 1 cs6292 cs6292 248418000 Aug 2 01:16 mx2t6-mn2t6-tp-20160401-day1to15-ecmf-all.grib
-rw-rw-r-- 1 cs6292 cs6292 248418000 Aug 2 01:44 mx2t6-mn2t6-tp-20160402-day1to15-ecmf-all.grib
-rw-rw-r-- 1 cs6292 cs6292 248418000 Aug 2 02:13 mx2t6-mn2t6-tp-20160403-day1to15-ecmf-all.grib
-rw-rw-r-- 1 cs6292 cs6292 248418000 Aug 2 02:44 mx2t6-mn2t6-tp-20160404-day1to15-ecmf-all.grib
-rw-rw-r-- 1 cs6292 cs6292 248418000 Aug 2 09:29 mx2t6-mn2t6-tp-20160405-day1to15-ecmf-all.grib
-rw-rw-r-- 1 cs6292 cs6292 248418000 Aug 2 10:19 mx2t6-mn2t6-tp-20160406-day1to15-ecmf-all.grib
-rw-rw-r-- 1 cs6292 cs6292 248418000 Aug 2 11:02 mx2t6-mn2t6-tp-20160407-day1to15-ecmf-all.grib
-rw-rw-r-- 1 cs6292 cs6292 248418000 Aug 2 11:55 mx2t6-mn2t6-tp-20160408-day1to15-ecmf-all.grib
This is an example of our request:
for member in members:
rep=server.retrieve({
'dataset' : "tigge",
'step' : "6/to/366/by/6",
'number' : member,
'levtype' : "sl",
#'date' : date,
'date' : jour,
'time' : "00",
'origin' : origin,
'type' : "pf",
'grid' : "0.281/0.281",
#'param' : parameter,
'param' : 'mx2t6/mn2t6/tp',
'area' : "67.023/275.977/42.012/311.838",
'target' : "mx2t6-mn2t6-tp-" + jour + "-day1to15-" + origin + "-" + member + ".grib"
})
We go day per day during the download.
We already downloaded a big amount of data a few months ago (about 9 months ago) and it has quite different, it ran really quickly compared with now. Can you please give us your advise? Is there a way to go quicker?
Thank you
Tito
Manuel Fuentes
Hello Tito... this is not the place for this kind of query... I'd let somebody else look after that aspect and move this to an FAQ or similar...
The delays you experience are likely due to the interpolation (regridding) requested. NCEP data is encoded with JPEG compression, which is very costly to decompress (costly = it takes much longer than GRIB's simple packing used for ECMWF data). If you look at the log output of each job, it should mention how long was spent in the interpolation of the data.
Unknown User (userf8cb9d)
Please help me.
The error like this :
ars - ERROR - 20181128.031436 - undefined value : ncep for parameter ORIGIN
mars - ERROR - 20181128.031436 - Values are :
ORIGIN
mars - ERROR - 20181128.031436 - Ambiguous : ti could be TURKEY or TEST
mars - FATAL - 20181128.031436 - No request
Traceback (most recent call last):
File "D:\python\api\example.py", line 29, in <module>
'target' : "NCEP_2016_0012.grib"
File "D:\python\api\ecmwfapi\api.py", line 520, in retrieve
c.execute(req, target)
File "D:\python\api\ecmwfapi\api.py", line 463, in execute
self.connection.wait()
File "D:\python\api\ecmwfapi\api.py", line 360, in wait
self.call(self.location, None, "GET")
File "D:\python\api\ecmwfapi\api.py", line 140, in wrapped
return func(self, *args, **kwargs)
File "D:\python\api\ecmwfapi\api.py", line 340, in call
raise APIException("ecmwf.API error 1: %s" % (self.last["error"],))
APIException: u'ecmwf.API error 1: Bad request'
And my example:
from ecmwfapi import ECMWFDataServer
# To run this example, you need an API key
# available from https://api.ecmwf.int/v1/key/
server = ECMWFDataServer()
server.retrieve({
'origin' : "ncep",
'levtype' : "Surface",
'dataset' : "tigge",
'step' : "0/6/12/18/24/30/36/42/48",
'grid' : "2/2",
'time' : "00/12",
'date' : "2016-01-01/to/2016-02-01",
'area' : "55/96/35/130",
'param' : "165",
'type' : "fc",
'target' : "NCEP_2016_0012.grib"
})
Carsten Mass
Shuijan,
The valid origin for NCEP in MARS is kwbc. You can find this by selecting some NCEP data on http://apps.ecmwf.int/datasets/data/tigge/levtype=sfc/type=cf/ and clicking on "View the MARS request" or from the centre keys at http://apps.ecmwf.int/codes/grib/format/mars/centre/.
Unknown User (userf8cb9d)
Thank you very much